
Shang Yang
Shang Yang
I am a third-year Ph.D. student at HAN LAB of MIT EECS, advised by Prof. Song Han. My long-term goal is to build efficient machine learning systems for applications at different scales, especially the Large Language Models (LLMs). Recently, I am activately working on the efficient inference systems for LLMs/VLMs.
News
- [2025/11] 🏆 TLT, our efficient RL framework for reasoning LLMs, has been accepted by ASPLOS 2026!
- [2025/05] 🔥 I presented QServe and LServe at MLSys 2025! [QServe Video] / [LServe Video]
- [2025/02] 🏆 Both QServe and LServe have been accepted by MLSys 2025!
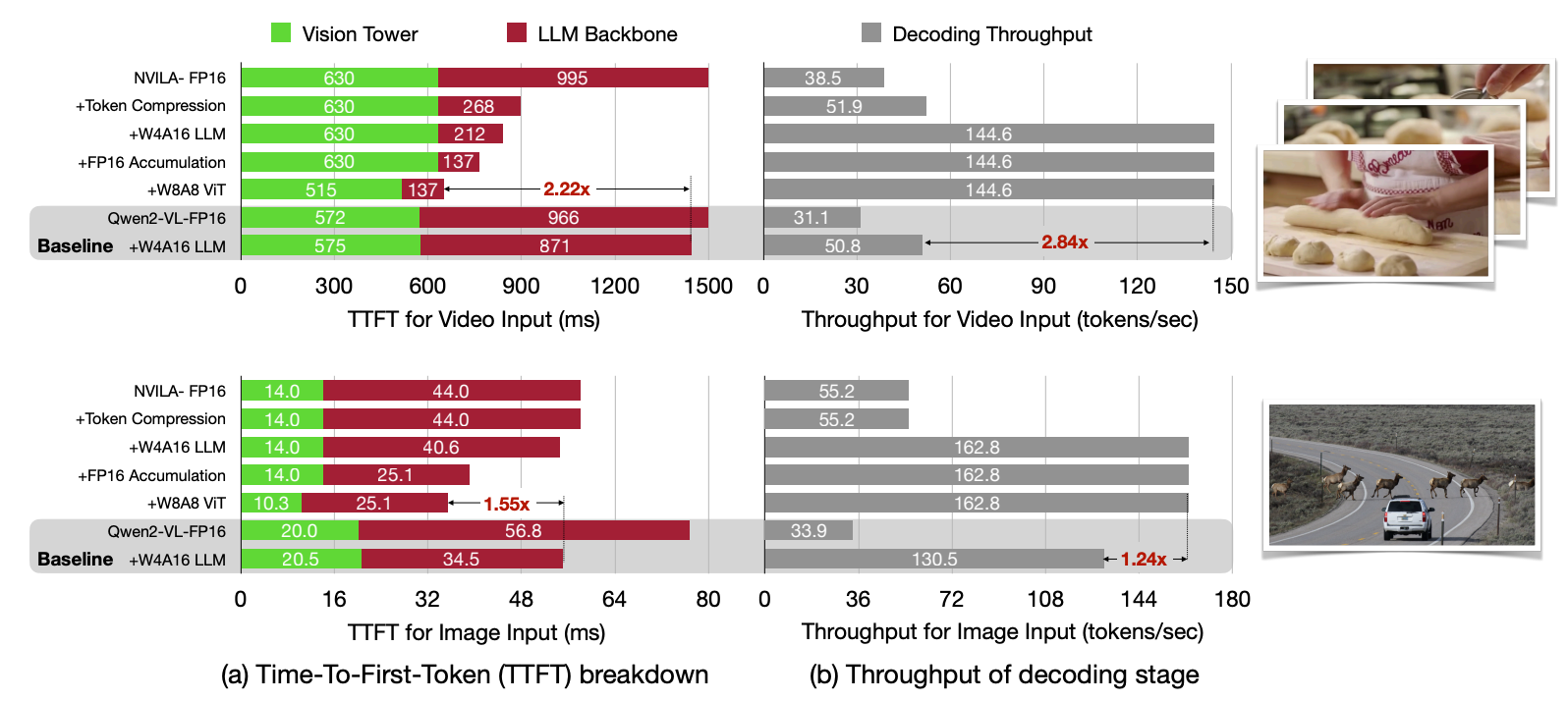
- [2025/02] 🔥 We released LServe, substantially accelerating long-sequence LLM inference with Unified Sparse Attention.
- [2024/05] 🔥 We released QServe, an efficient large-scale LLM serving framework with W4A8KV4 Quantization.
- [2024/05] 🏆 AWQ&TinyChat receives the Best Paper Award of MLSys 2024!
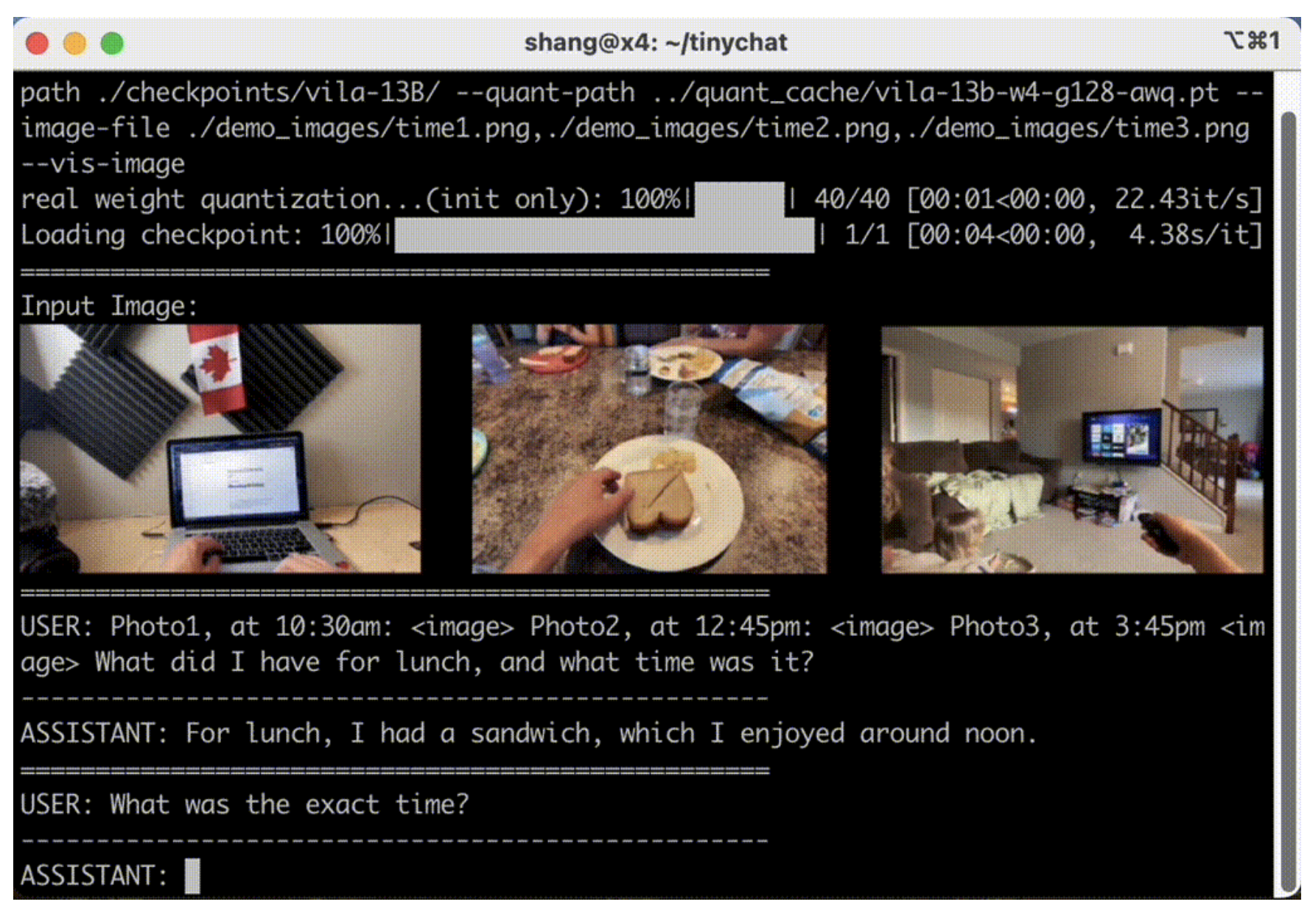
- [2024/03] We have released an updated version of TinyChat. Visual Language Models (e.g. VILA) are supported! Play with our demo!
- [2024/02] 🔥 AWQ is accepted by MLSys 2024!
- [2023/10] 🔥 I presented TorchSparse++ at MICRO 2023! See the video and slides here!
Selected Publications
-
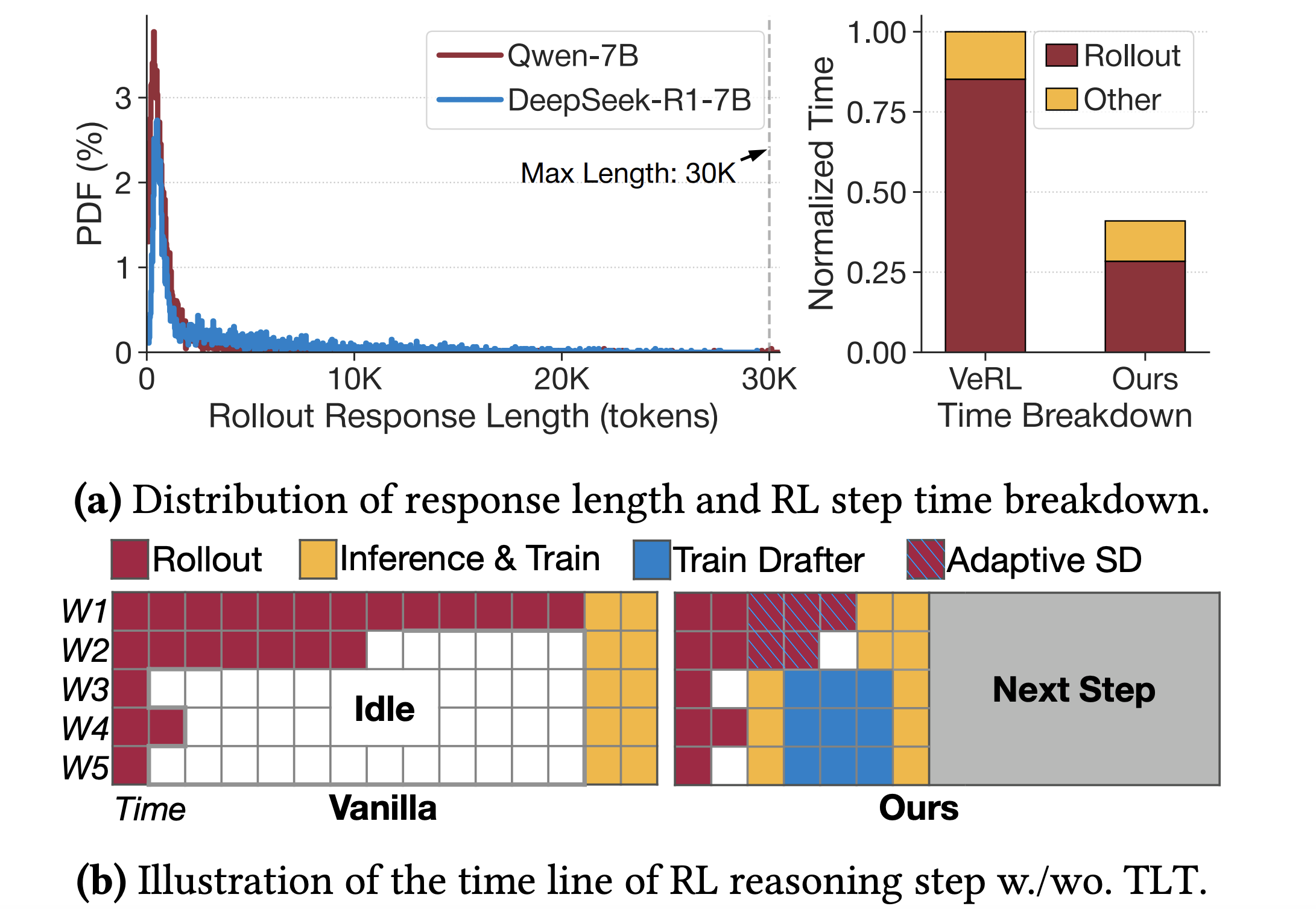 ASPLOS
The 31th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2026.
ASPLOS
The 31th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2026. -
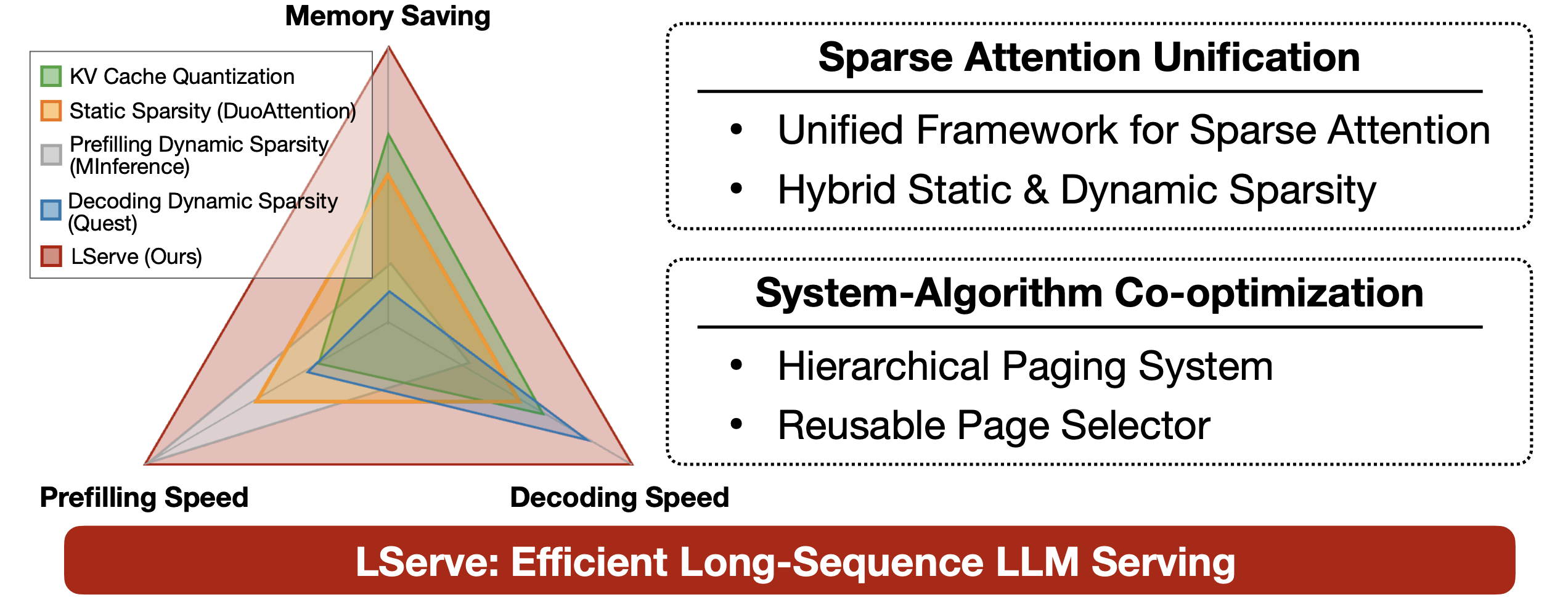 MLSys
The Eighth Annual Conference on Machine Learning and Systems (MLSys), 2025.
MLSys
The Eighth Annual Conference on Machine Learning and Systems (MLSys), 2025. -
 MLSys
The Eighth Annual Conference on Machine Learning and Systems (MLSys), 2025.
MLSys
The Eighth Annual Conference on Machine Learning and Systems (MLSys), 2025. -
 MLSys
The Seventh Annual Conference on Machine Learning and Systems (MLSys), 2024.Code Best Paper Award
MLSys
The Seventh Annual Conference on Machine Learning and Systems (MLSys), 2024.Code Best Paper Award -
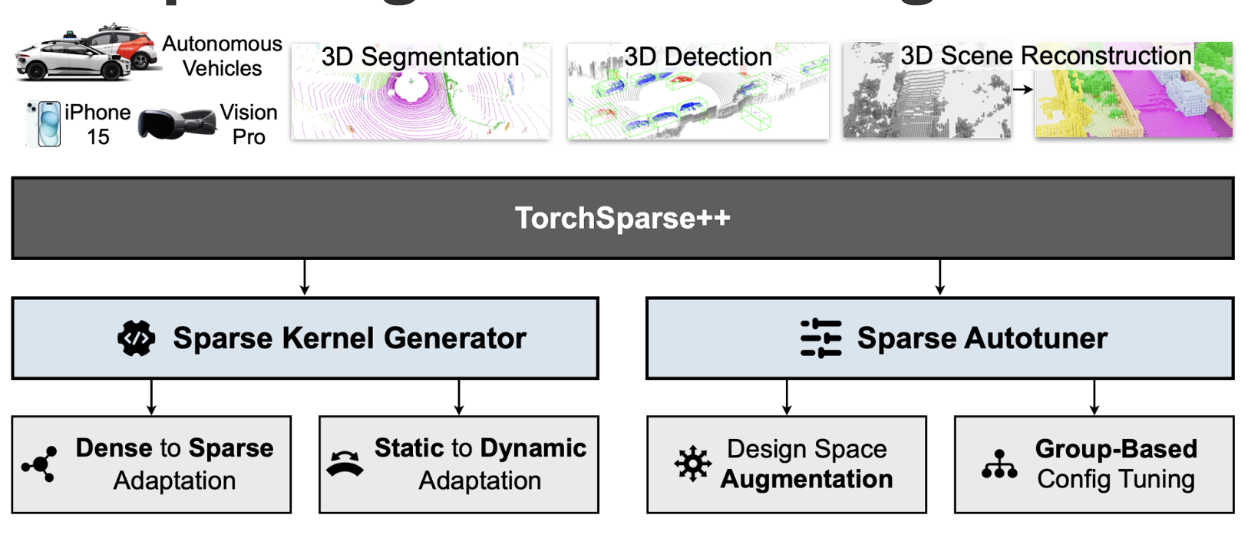 MICRO
56th IEEE/ACM International Symposium on Microarchitecture (MICRO), 2023.
MICRO
56th IEEE/ACM International Symposium on Microarchitecture (MICRO), 2023.
Blogs

© Copyright 2024 Shang Yang. Powered by Jekyll and Minimal Light theme.